
检索设置 - qKnow 开源版
2026/5/11大约 3 分钟用户手册
功能概览
检索设置模块用于配置知识库的检索参数,包括检索方式、权重设置、Top K值、Score阈值和ReRank模型等,帮助优化知识库的检索效果和准确性。
主要特性
- 🔍 多种检索方式:支持向量检索、全文检索和混合检索三种方式
- ⚙️ 权重设置:支持调整语义匹配和关键词匹配的权重分配
- 📊 阈值控制:支持设置Score阈值过滤检索结果
- 🔄 ReRank模型:支持配置重新排序模型优化检索结果
操作指南
检索设置页面
点击【知识库】→【知识库设置】→【检索设置】,进入检索设置页面。页面分为检索方式、权重设置和ReRank模型三个配置区域。
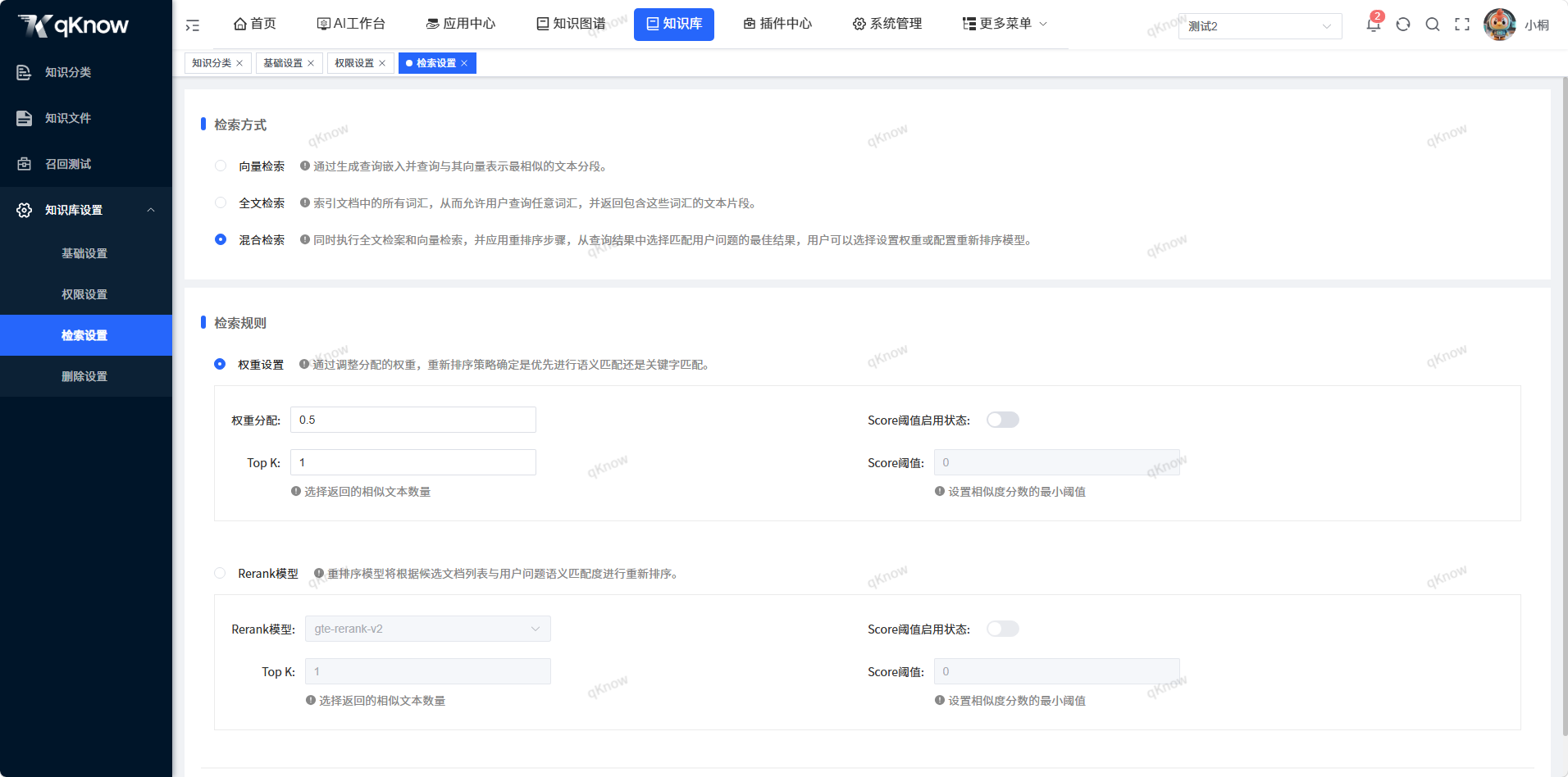
配置检索方式
在检索方式区域选择合适的检索模式:
| 检索方式 | 说明 |
|---|---|
| 向量检索 | 通过生成向量嵌入并查询与其向量表示最相似的文本分段 |
| 全文检索 | 索引文档中的所有词汇,允许用户查询任意词汇,并返回包含这些词汇的文本片段 |
| 混合检索(推荐) | 同时执行全文检索和向量检索,并应用重新排序策略,从查询结果中选择匹配用户问题的最佳结果 |
配置权重设置
在检索规则区域配置权重参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
| 权重分配 | 调整语义匹配和关键词匹配的权重比例 | 0.5 |
| Top K | 选择返回的相似文本数量 | 1 |
| Score阈值启用状态 | 控制是否启用Score阈值过滤 | 关闭 |
| Score阈值 | 设置相似度分数的最小阈值 | 0 |
配置ReRank模型
在ReRank模型区域配置重新排序参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
| ReRank模型 | 选择重新排序模型 | gte-rerank-v2 |
| Top K | 选择返回的相似文本数量 | 1 |
| Score阈值启用状态 | 控制是否启用Score阈值过滤 | 关闭 |
| Score阈值 | 设置相似度分数的最小阈值 | 0 |
保存配置
配置完成后,点击页面底部的【保存】按钮,保存所有检索参数配置。
常见问题
召回数量设置多少合适?
召回数量(Top K)取决于具体的业务场景和用户需求。建议根据实际测试结果调整,平衡检索准确性和响应速度。较小的Top K值可以提高响应速度,较大的Top K值可以返回更多相关结果。
相似度阈值的作用是什么?
相似度阈值用于过滤不相关的文档,只有相似度高于阈值的文档才会被返回。阈值越高,返回的文档越相关,但可能会遗漏一些边缘相关的文档。建议根据实际需求设置合适的阈值。
什么是ReRank模型?
ReRank模型用于对初步检索结果进行重新排序,根据语义匹配度对结果进行优化排序,从而提高检索准确性。启用ReRank模型可以显著提升检索效果,但会增加一定的计算开销。